Version Control
Version control, in the context of continuous integration and delivery (CI/CD) for firmware development, serves as the backbone for well defined software releases that can be rolled back and updated in a predictable manner.
You’re likely familiar with the basic principles of version control systems like Git. However, version control in this broader context of DevOps is a lot more than just using git effectively.
Good version control involves understanding of:
-
Branching Strategies: adopting the most efficient branching strategy that scales from one developer to hundreds is very important for frequent releases with minimal technical debt. With the wider adaptation of code collaboration platforms like GitLab combining feature branching with efficient code reviews and trunk based development strategy has become easier, more scalable and more efficient at scale.
-
Release versioning: when your project grows beyond one repository, the need for versioned artifacts grows exponentially. Versioning applied to release artifacts is what keeps a large ecosystem of software together. It makes your project dependable in the sense that others can depend on specific versions of your product.
-
Deployment and Rollback: In continuous delivery, the ability to quickly deploy and, if necessary, rollback changes is crucial. Version control, integrated with your deployment tools and a solid versioning strategy allows for smooth deployment of specific versions to production environments. Should an issue arise, the team can easily revert to a previous, stable firmware version along with all necessary dependencies, minimizing downtime and potential issues in the field.
-
Reproducibility.: when you apply version control across projects you can go back to a previously built version of the software and be able to rebuild it with the same versions of all dependencies. This is not possible unless all of your build infrastructure is under version control and is written as code.
Branching
The ability to create branches, or versions of the project, in a codebase is a first class feature of every version control system like git. Branching allows us to work on multiple features at the same time in the same project without these features affecting each other.
Three of the most useful commands in git are creating a branch, fetching remote changes and then rebasing the branch on top of the new changes:
git branch -b <branch name> origin/main: create a new branch from the main trunk.git fetch --all: fetch latest changes from all sources.git rebase origin/main: rebase the current changes on the latest version of main.
Branching may seem like a great way to solve many problems affecting the process of software development on large teams. However, the requirement to bring changes in branches branches back into main depository means it’s important to have a sensible process for branching that can scale.
I personally never use traditional merging in my daily workflow and I think that merging is completely unnecessary 99% of the time when working on a large project with tens of developers. My goto strategy is always trunk based development where changes are rebased on main trunk as opposed to being merged. My branches are very short lived (at most a few days) and when using CI automation like what is provided by GitLab I’m able to implement trunk based development in a very efficient and scalable way.
There is a tension between using branches and continuous integration. If different members of the team are working on separate branches or streams, then by definition they’re not continuously integrating. The most important practice that makes continuous integration possible is that everybody tries to merge their changes to main at least once every few days. So if merge requests are being merged continuously into main then your team is doing things right.
Merge requests
The merge request should be the primary way that you get changes into the main repository. This allows us to automatically check the software for correctness before we add the change to main trunk and share it with other developers (who will then rebase their branches on the updated main branch and continue their work).
Merge request automated checks should enforce:
- Coding style: use tools like
clang-tidy,autopep8,pylintetc to check coding style. Make these hooks run aspre-commithooks and runpre-commit run --all-filesin CI job to run all checks against all files. - Unit tests: unit tests should always be executed against every merge request before it can be allowed to be merged. Use code coverage as guidance and make sure it is high enough to ensure that unverified code is kept to a minimum before changes are merged.
- Integration tests: software component integration tests must both run and be required to pass before a merge request is merged.
- Deployment test: your deployment scripts should preferably also run as part of each merge request to verify the deployment. This should not be a heavy deployment, just a way to be sure that deployments work before you merge.
- System and end-to-end tests: these tests should run against deployed firmware. You should use the same deployment method as you use in production deployments and then run end to end tests against the deployed firmware to make sure the final product is working.
If you do at least all of the above in your merge request pipelines then you can have a very high degree of confidence that your firmware is always in high quality working state on the main branch of your repository.
Your merge requests should ideally be:
-
Independent - meaning that at any given time all developers should work on tasks that do not depend on each other. Dependent tasks should never be worked on in parallel - rather they should be serialized so that any open merge requests at any given time are as independent as possible.
-
Focused - only include changes that accomplish the deliverable that needs to be produced to mark the task corresponding to the MR as completed. This may mean making changes to many files - but you should not combine multiple logically separate changes together into one merge request. Keep the main thing the main thing. (for this to work, your task definitions themselves should focus only on one deliverable at a time).
-
Verifiable - your infrastructure should support running enough tests to generate “proof” that the deliverable has been completed. Usually the proof is in the form of running a series of scenario tests where the deliverable needs to be used. Your pipeline should automatically fail if the proof can not be verified (for example if any of the tests fail).
Merge requests ensure that code is continuously integrated, that developers pick up each others’ changes immediately and they help you avoid ‘merge hell’ or ‘integration hell’ when it is time to make a release.
Code reviews
Another very important benefit of adopting merge request oriented trunk based development workflow is that it makes code review easy as well.
While the developer works on finalizing the merge request and making sure all pipeline jobs pass, code reviewers can take a look at the changes in the merge request using Gitlab UI and provide comments and feedback.
Code review should catch problems like:
-
Architectural issues: is the code structured well, is it portable, is it sufficiently decoupled?
-
Logical errors: are there misunderstandings around how the system should work? Sometimes developers can implement both code and tests but the assumptions of how things should work are wrong and so it is up to the code reviewer to catch this.
-
Lack of code reuse: review should catch duplications and implementations that can be replaced by reusing existing libraries.
Definition of done
Make sure that merge requests are completed in full. Even as the project evolves and implementation is iterated, the work that has been previously merged should preferably not require much refactoring. Do as much refactoring as possible in the merge request and merge fully completed work.
Avoid the temptation to merge half-done work and the reasoning that comes with it.
Gitlab Configuration
- Protected main branch: we don’t want any changes pushed directly to main.
We can disable this by making the main branch protected. In gitlab this can be
done under
Settings > Repository > Protected branches. Nobody should be able to push to the main branch at all - all changes will have to pass through merge requests.

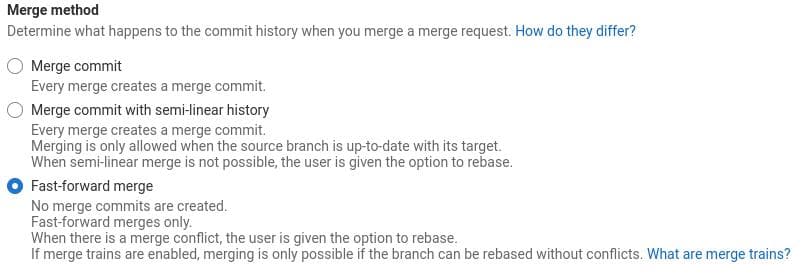
- Disable merge commits: use squashed commits instead. This helps keep the
main branch history clean and ensures that every commit on the main branch is
working (since it should always pass all tests before merge request is merged)
. Disable merge commits under
Settings > General > Merge Request > Merge Method:
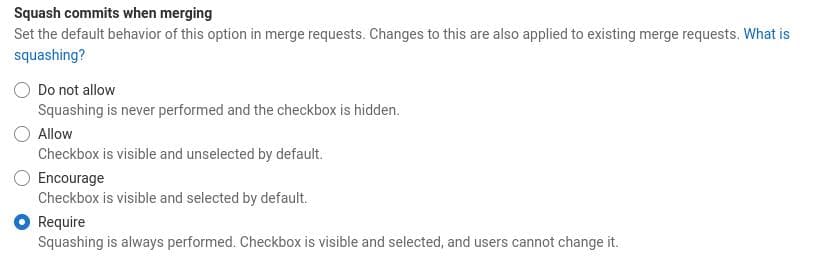
- Enable squash commits: This will ensure that all of our commits that go into a merge request during review are combined into just one commit in the main branch:
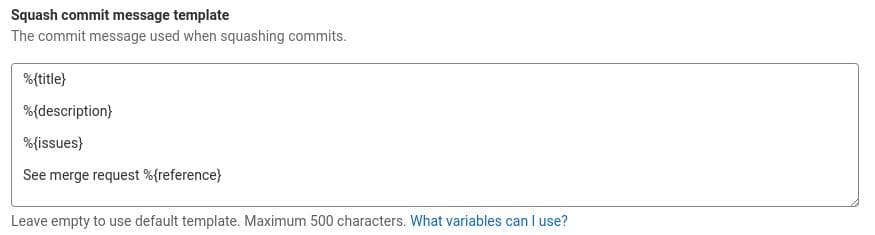
- Use merge request description for squash commit message: this ensures we save the details of the merge request in the repository as well.
- Make sure green pipelines are required: this ensures that nothing can be merged unless it passes all checks. You should also make sure that discussions are resolved before merge can proceed.

- Use merge request templates: to have a consistent structure of merge
request description and subsequent commit messages you can create merge
request templates in markdown and store them in
.gitlab/merge_request_templates/. Gitlab will automatically pick up all markdown (.md) files there and these will appear as templates when creating a merge request. Link to gitlab documentation ).
What to version control
The short answer is: everything. You should be able to rebuild everything including your whole development environment from scratch at any time using only files in your git repositories.
-
All application code and dependencies as well (for example libraries, content etc). A good way to link git repositories is through manifests (as opposed to git sub-modules).
-
Test data used to pre-compile portions of the code or create reference data for tests. Do not just commit results of any calculations - commit calculations themselves and preferably include them into documentation.
-
Development environment: You can use
Dockerto build your development environment and all your other infrastructure should also be store in version control. Either in the same repository or in several repositories. -
Automated tests: you can write your tests in any language but make sure everything is automated and always verified in CI.
-
Migration scripts: if your data model for the database needs to be migrated then automate this using migration scripts and store these scripts in the repository.
-
Documentation: texts that describe how to use your software, how to use the source code, how to extend the code with new features. All of this should be part of your documentation and the whole documentation should be buildable from source to produce deployable artifacts like html pages or PDFs.
-
Any other configuration files or scripts that are needed to create infrastructure for deployment and testing. The source repository should contain all sources that are needed to download all tools, build the software, test it and deploy it.
Versioning of dependencies
- Bumpversion: this is a python utility that you can use to increment version number of your project.
[bumpversion]
current_version = 0.4.1
commit = False
tag = False
parse = (?P<major>\d+)\.(?P<minor>\d+)\.(?P<patch>\d+)(\-(?P<release>[a-z]+)(?P<build>\d+))?
serialize =
{major}.{minor}.{patch}-{release}{build}
{major}.{minor}.{patch}
[bumpversion:file:package.json]
search = "version": "{current_version}"
replace = "version": "{new_version}"You can now run bumpversion patch to increment patch version, bumpversion minor to reset patch version to zero and increment minor version and
bumpversion major to increment the major version. Use semantic versioning to
device when to increment each number.
- West: if you are building on the Zephyr infrastructure then
westis the main tool you will use for managing versioning of code dependencies. Make sure all your dependencies follow a well defined release process and publish versions using tags in git so you can select specific versions in yourwest.ymlconfig.
manifest:
self:
path: app
remotes:
- name: zephyr
url-base: https://github.com/zephyrproject-rtos
projects:
- name: zephyr
remote: zephyr
revision: v3.4.0- Use gitlab automatic release function: this helps you tag a version and
make an official release that will appear under
Releasessection in your repository. It also guarantees that you can’t make the same release twice. This is important. You want to always be forced to bump the version number before publishing a release.
release:
stage: release
image: registry.gitlab.com/gitlab-org/release-cli:latest
allow_failure: true
rules:
- if: $CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH
- if: $CI_PIPELINE_SOURCE == "merge_request_event"
when: never
script:
- echo "Making a release"
release:
name: v0.4.1
tag_name: v0.4.1
description: 'Official release'
needs: ["deploy:production"]The above is an example of how to configure it in gitlab. This job will run on
default branch (main) and will tag the release with a specific number.
Bumpversion helps making sure that we update these numbers in a systematic way
(just add your .gitlab-ci.yml as a section to the .bumpversion.cfg config.
Project checklist
Use this checklist to verify that you are applying principles of version control in your project.
-
Application code: What percentage of the application code is using version control? Is it easy to recover a specific version of the application with all necessary dependencies and produce a binary output of that version? When rolling back to an old version, are older versions of all dependencies used as well or are these links broken upon rollback? In 2024 this number is likely always 100%, but just in case.
-
Configuration: What percentage of your system configuration is in version control? Can the team quickly build any version from version control? What about installing compilers, toolchain, other tools needed to build the software? Do versions of these tools matter for development and can you guarantee that final output of the build is exactly the same in 2 years as it is today for current version of the software? Can you guarantee that you can use the same versions of build tools for an older build? Build your own docker images from configuration that you manage.
-
Databases: What percentage of the application configuration is in version control? Do you use version control to track all configuration parameters used for different deployment targets of the application and for different customers? Is it possible to quickly get configuration parameters for an old version of the application? Is it possible to build all custom releases without manual effort directly from version control?
-
Build and deployment scripts: What percentage of the build scripts and build configuration is in version control? Are all of these files tracked continuously in the same repository or are they in different repositories? Is it easy to step up to a different version later without issues and without affecting older versions?
All of these points are very important the degree to which your team is able to implement them is the degree to which your team is able to quickly adopt to changes in customer requirements while also being able to support older releases delivered to other customers.
Tools
-
Git: The most advanced and feature rich version control software today is
git. Git has many tools built on top of it like IDE plugins and terminal utilities liketig. -
West: implements better features than git submodules and is useful for projects outside of Zephyr for managing multi-repository source level dependencies.
-
Bumpversion: this enables us to apply
semantic versioningto our project and update version numbers across multiple files.
Recommendations
Here are a few recommendations around version control.
-
Avoid long lived branches: this creates multiple sources of truth in the project which diverge over time and merging them becomes increasingly more difficult. Instead, continuously rebase work in progress on the main trunk to keep this work up to date.
-
Avoid basing new work on work in progress: this makes it complicated to avoid conflicts. Focus instead on having short lived branches and always base new work on main branch. If you really need to start new work on top of an existing feature branch then do so but don’t rebase or merge new changes from the feature branch. Instead, after the feature branch has been merged, do an interactive rebase on top of main and drop the commits that came from the base branch that has been merged.
-
Adopt trunk based development: it is one of the best enablers that make efficient scrum workflow easy to implement. In fact, it is so important that the next section is entirely dedicated to it.

Get a focused reply on your firmware challenge
Share your target hardware, OS, and current blocker — you'll get a tailored response within 1–2 business days with concrete next steps.
Fastest path: LinkedIn
Message on LinkedIn with your details, or use the form below.
Want an overview of services? Visit the firmware page.